Skip to Navigation
Skip to Content
☰
Pricing
Login
Solutions
For Healthcare
For Education
For Service Providers
For Enterprises
For SMBs
Products
ThreatSTOP Platform
DNS Defense
DNS Defense Cloud
IP Defense
One-Click Sanctions Compliance
For AWS WAF
Enhanced OFAC AWS WAF Managed Rules
For AWS Route 53
MyDNS
Community Edition
Marketplace
FirstSTOP
Resources
Blog
Collateral
Video
Documentation
API Docs
Check IoC
Company
Who We Are
What We Do
Careers
Contact Us
Partners
Channel
OEM
Technology
MSSP
Blog
Start Now
Search...
×
Topic: malicious IP
Blocklists
PDNS
Botnets
Ransomware
Search blog...
×
Popular posts in the last 30 days
1
2
>
Subscribe to the ThreatSTOP blog
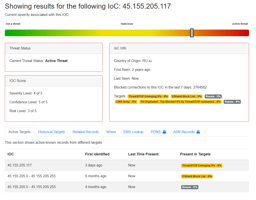
![45.146.165[.]168 exploiting Log4j is another reason to block Selectel](https://www.threatstop.com/hs-fs/hubfs/selectel_ip_virustotal.png?width=400&height=200&name=selectel_ip_virustotal.png)
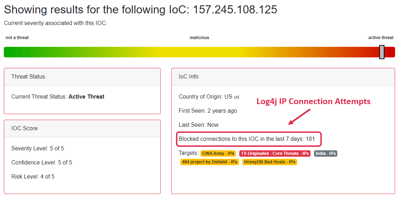




![ChinaNet IP 14.135.120[.]19 has one heck of a bad reputation](https://www.threatstop.com/hs-fs/hubfs/chinanet_ip_targets.png?width=400&height=200&name=chinanet_ip_targets.png)
![More Love from Russia - More Bad IPs by Selectel like 45.146.164[.]38](https://www.threatstop.com/hs-fs/hubfs/ip_selectel.png?width=400&height=200&name=ip_selectel.png)